
Introduction
Streaming data is a common characteristic seen in modern software systems. Understanding incoming data even before it gets into an analytics store is imminent with businesses aiming for real time updates. Stream processing has wide range of applications including anomaly detection, personalized customer experience, access to real-time data visibility etc., In this blog, ksqlDB , a stream processing abstraction, is discussed in its capacity to build a streaming data pipeline.
, a stream processing abstraction, is discussed in its capacity to build a streaming data pipeline.
Problem Domain
For this blog, let’s consider the Bike Sharing Systems (BSS) used in major cities today. To explain BSS briefly – Docking stations are spread across the city. Each docking station has a bunch of docking slots. Bikes can be hired at docking stations and the users are charged until it’s docked back at a station slot.
The most common challenge these systems face is the Balancing problem or the Repositioning problem i.e., Docking stations are either full or empty.
Approach
Understanding mobility patterns helps BSS operators to device an optimal strategy to make the bikes available during a time of the day at a particular station. And for sudden spikes, BSS operators usually solve the asymmetric demand by repositioning bikes from top destination stations to top origin stations. There are other approaches to reposition bikes, but they are beyond the scope of this blog.
Assuming events for bikes and slots availability at each docking station are streamed as station status, ksqlDB helps in enriching the bike availability events by joining station status events (containing docks and bike availability at stations) with their corresponding docking station details like name, latitude/longitude, capacity etc., This way the events are made readily usable by OLAP stores for analytics/visualization and other downstream dependent services.
ksqlDB Constructs
ksqlDB is a combination of the following three things
Compute Engine - to filter, mask, transform and build/join streams of events using SQL syntax
Runs embedded Kafka Connect connectors - to connect with a wide range of external sources and sinks
Materialized views builder – a disk based RocksDB store for faster search and retrieval
Along with the above powers, ksqlDB can also be scaled, secured and monitored as a single unit.
Reference Solution
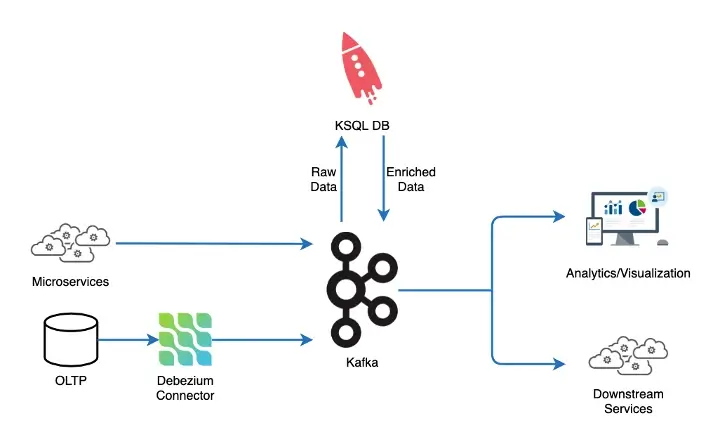
Details of docking stations rarely change and are usually maintained in an OLTP store. A CDC system likeDebeziumcan be used to build an initial snapshot of the entire table and incremental changes as a sequence of events on a Kafka topic. ksqlDB can then build aKTablefrom this topic, a materialized view of the table on a disk-based DB. This can then be made available to make joins with a Kafka Stream, i.e., data-in-motion.
Schema for the station availability and station information are taken fromGlobal Bike Feed Specification
Sample query to createKStreamfrom station status events
CREATE STREAM STATION_STATUS (STATION_ID VARCHAR,
NUM_DOCKS_AVAILABLE INT,
NUM_BIKES_AVAILABLE INT,
LAST_REPORTED INT)
WITH (KAFKA_TOPIC='bss.station_status', VALUE_FORMAT='json')Sample query to create KTable for station information events
CREATE TABLE STATION_INFO_TABLE (STATION_ID VARCHAR PRIMARY KEY,
STATION_NAME VARCHAR,
ADDRESS VARCHAR,
CAPACITY INT,
LATITUDE DOUBLE,
LONGITUDE DOUBLE)
WITH (KAFKA_TOPIC='bss.station_info', KEY_FORMAT='KAFKA', VALUE_FORMAT='json')With ksqlDB, KStreams can be created using SQL syntax that then runs as a persistent stream query on ksqlDB infrastructure. Persistent stream query is just a KStreams application under the hood. Joining a stream with a KTable by primary key produces an enriched stream of events with details from two topics merged together as below
CREATE STREAM ENRICHED_STREAM
AS
SELECT SS.STATION_ID AS STATION_ID, SI.STATION_NAME AS STATION_NAME, SI.ADDRESS AS ADDRESS,
SI.CAPACITY AS CAPACITY, SI.LATITUDE AS LATITUDE, SI.LONGITUDE AS LONGITUDE,
STRUCT("lat" := SI.LATITUDE, "lon" := SI.LONGITUDE) AS LOCATION,
SS.NUM_BIKES_AVAILABLE AS NUM_BIKES_AVAILABLE, SS.NUM_DOCKS_AVAILABLE AS NUM_DOCKS_AVAILABLE,
SS.LAST_REPORTED AS LAST_REPORTED
FROM STATION_STATUS_STREAM SS
JOIN STATION_INFO_TABLE SI
ON SS.STATION_ID=SI.STATION_ID
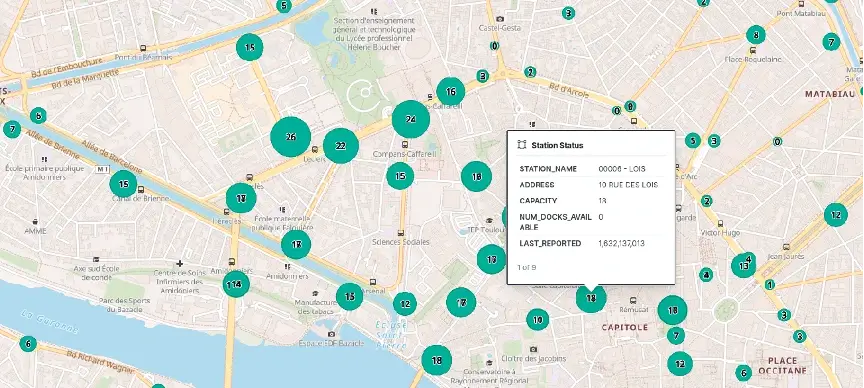
EMIT CHANGES;The merged data can then be sent to a store likeElasticsearchand visualized in real-time with Kibana
Advantages
Persistent Queries does all the hard work on ksqlDB layer, which otherwise would have been an application logic, with low latency as it stays closer to data
State store to perform aggregations on a disk-based DB provides performance advantage
Ability to run embedded Kafka Connect connectors removes the need to manage separate data integration infrastructure from compute
Summary
With the abilities to perform stateless transformations and stateful aggregations over streams, providing accessibility via SQL, it makes ksqlDB a hard component to be looked over when building a streaming data pipeline.
Talk to us for more insights
What more? Your business success story is right next here. We're just a ping away. Let's get connected.
