
Image to Card: Behind the scenes
In continuation to Part 1 of this series (in case you have missed it, check it out here - Part 1), we'll dive deeper and discuss the technical aspects of Pic2Card in this part.
Let us see ademo of how this works
of how this works
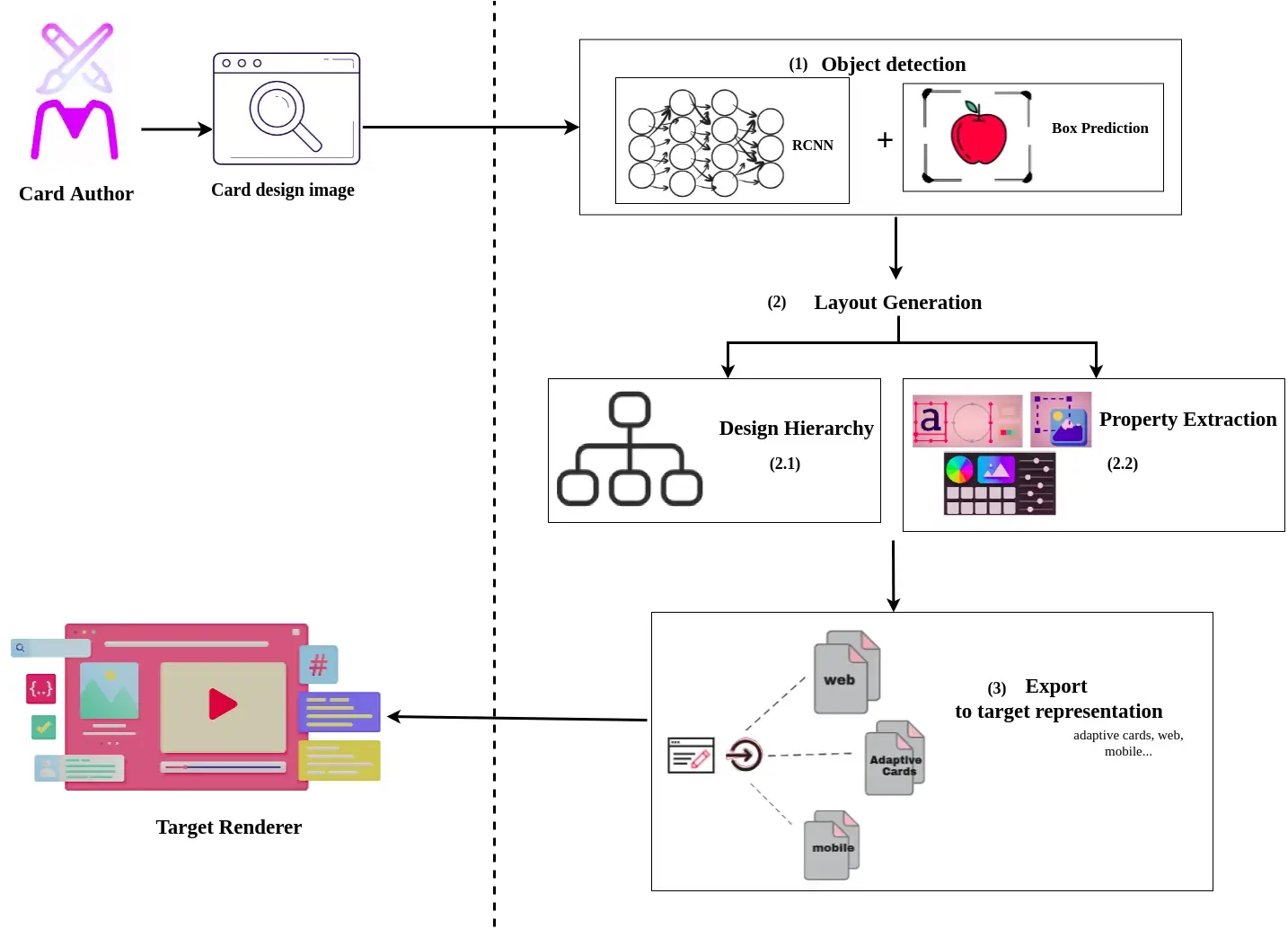
At a high level, it focuses on 4 tasks.
Firstly, the object detection phase, where we try to detect and classify the GUI design elements along with their position details [ boundary boxes of each element] from the given GUI design image.
Object recognition
For the GUI elements detection, we have applied the Object-Detection method. We performed transfer learning of our custom dataset having the GUI design elements as an object to be trained, on the pre-trained Faster R-CNN model [One of the RCNN family models] by Google using TensorFlow.

Once the design objects are identified the model returns us the list of detected objects + their bounding boxes i.e., its position in the image. Using these bounding boxes and element classes returned from the model we perform 2 tasks in parallel: Layout Generation and Property Extraction
Layout generation
As one of the parallel tasks in the second phase of our pipeline, we try to understand the element's design hierarchy. We have split up the design structure understanding into 2 sub-tasks
At first, we will rearrange the detected design elements in a hierarchical structure of rows and columns using the bounding boxes which will give us the detected design element’s row-column wise hierarchy.
Once the design elements are re-structured into rows and columns, using this hierarchal data structure we will group the design elements into their respective design containers, which could finally represent a UI design structure in items of root + container level hierarchy.

For Example


Property Extraction
The second sub-task to be run in parallel during the layout generation is the Property Extraction. As the name suggests, we are trying to extract the detected design element's properties or the design attributes. Each design element has its specific set of properties, we will see a few of the major properties in detail.
In order to improve the performance of the property extraction, the detected design objects undergo a series of image pre-processing steps such as grayscale conversion, noise reduction, and addition of padding pixels on all sides.
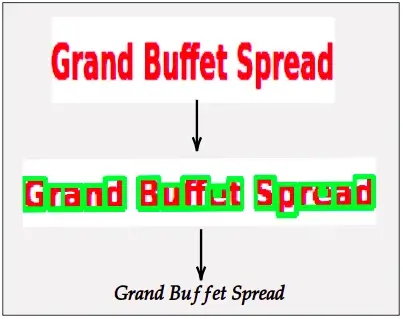
Text Extraction
One of the widely tagged properties among the design objects is the “text” value of the object. All the bounding boxes of the design objects which needs text extraction must undergo the OCR (Optical Character Recognition) process. We use tesseract as the OCR engine configured with the default language as English and PSM set to 6. Using the bounding box information, we crop the design object out of the GUI design image and treat this cropped region as a block of text [a line or a paragraph] to improve the text extraction precision. Defining this property extraction process per bounding box level helps to parallelize the extraction process.
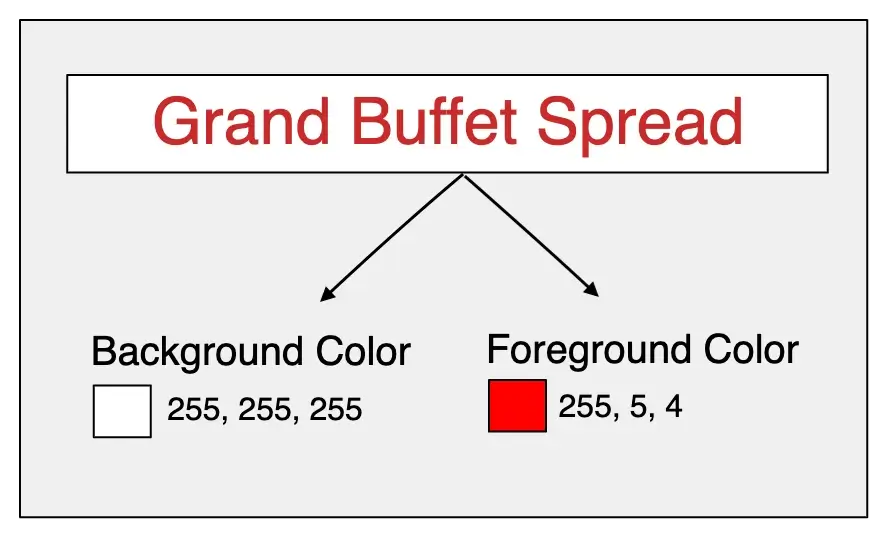
Font Color Extraction
We try to crop out the desired resign of color extraction and quantize the color palettes into the 2 most dominant colors namely foreground, and background. Based on the reduced palette, we consider the second most dominant as the foreground color for the text color property. One of the challenging parts of this property is the ability to detect multiple text colors from a sentence or a paragraph.
Font Size & Weight Extraction
Since the adaptive cards provide the flexibility to the design elements to be rendered in different application configurations, it is crucial to identify the relative text size and weight values of all the design elements in such a way that they can be binned into different buckets like [Small, Medium, and Large].
In order to normalize the bin thresholds, we have used a couple of Digital Image processing techniques such as greyscale conversion, erosion, dilation, and morphological transformation as a noise reduction process followed by a plain averaging of the per word-level size provided by the Tesseract OCR's per character bounding boxes and for the font-weight, a simple mean estimate was not that accurate as it became more biased towards the lighter fonts. Therefore, we have done a few more Computer Vision-based operations such as binarization, pixel inversion, and some morphological transformations to calculate the white pixel count for the average estimate.

Image Size
It is imperative to re-size the image design elements concerning its surrounding design elements to avoid the image disproportionalities with the final exported adaptive card size. We are using the similar normalization & threshold binning methods used for the font size estimations, but in this case, we have evaluated the width & height ratios of the image design element for a set of test datasets using clustering techniques to bin the thresholds.
Alignment Detection
After extracting all the properties, it is important to fix the container-wise alignment for each design element [We have achieved root hierarchy-wise alignment in the layout structure extraction phase itself]. We use clustering techniques similar to the Image size extraction to fetch the normalized bin thresholds, but in the adaptive cards, the design element's alignment is represented as a horizontal position concerning its container's centre. Therefore, we performed a horizontal-midpoint analysis for a set of test datasets where the bin thresholds are represented as ratios of the horizontal mid-point of each design element concerning the parent container's width.
As a final stage of our Pic2Card prediction pipeline, the generated layout skeleton and the properties/attributes are merged and exported to the target platform's representation.
What the future holds
Synthetic Dataset generation
As the Adaptive Cards matures, In-order to catch up with the new element's releases, we need to perform continuous re-train of the model to understand the new design elements. The biggest challenge in this area is the availability of the data i.e., the quantity of the train data.
Heard of GIGO (Garbage In, Garbage Out)? It is a popular term in the data science realm that emphasizes the quality of the training dataset as much as the quantity of the training data.
Therefore, we came up with the idea of generating such synthetic datasets in the needed quantity & following the basics of the Adaptive Cards design template to retain the train data quality.
The synthetic dataset generation logic picks the input design element image samples randomly & uses a set of Computer Vision techniques such as masking [using bitwise operations], erosion, and vertical stacking to generate the automated adaptive card design image along with its element annotations in the configured format [Pascal VOC / COCO]
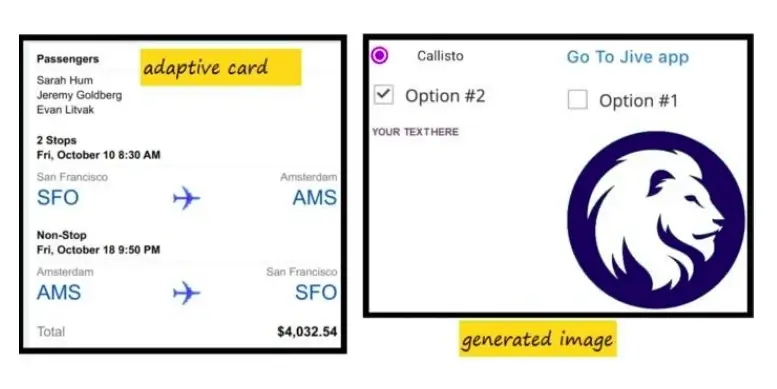
Image to prototype in one-click
The prospect of converting an image into a working prototype with a certain level of accuracy will transform the front-end development approach. As a sequel to the Adaptive Cards Image-to-Cards effort, we plan to replicate this approach for mobile and web application development as well. Yes, you heard it right. You just upload the image screens of your mobile application to receive a working prototype of IOS and Android apps.
We have kept the feature open source; you can find the source codes in our GitHub repository. If you have suggestions or would like to contribute to this project, please raise a PR athttps://github.com/BigThinkcode/AdaptiveCards
Talk to us for more insights
What more? Your business success story is right next here. We're just a ping away. Let's get connected.
