
Overview
Yes, you heard it right. In the Era of Cloud-First & Mobile-first, an offline-first approach is a must-have feature for many domains. Though the majority of the population has the Internet in their pockets, there are instances where applications should function without the presence of the Internet since Business continuity and contingency are inevitable for any organization.
Requirements
Secured application access is mandated irrespective of the network availability. A network or power outage during emergencies should not hinder accessibility. Health care professionals, mining/shipping industries, poor connection areas, etc., are a few examples of these.
With the increase in applications moving to Cloud, A Zero trust model is followed to secure the data. Operations like Defence and Military bases, Judiciary departments are considered more vulnerable with the application data constantly traversing through the Internet. This attracts the hackers and middle man and compromises confidentiality.
Solution Approaches
There are many approaches available for offline architecture however, choosing the right solution for the right business is crucial. The first step begins with having an adequate understanding of the business requirements to select the optimal offline solution. The following sections discuss the key components, scenarios, and recommendations for the same.
Data Optimization
The first step in designing an offline system is to handle the sheer volume of data processed at the server end and to sync with clients. Data optimization can be achieved by processing a specific set of data with a time frame, location, etc., for effective data syncing.
Once FTS (First Time Sync) is executed to sync all the necessary data for the application, the recurrent data sync can be managed by adopting Delta sync. With Delta sync, only the modified data is synced.
Sync Cycle
The Sync cycle is vital for any offline architecture since it defines the complete functionality of the application. The balance between offline and online data is determined by the Sync cycle. Choosing the right sync cycle is based on the network availability of the user, the significance of the data, and the business requirement to avail business continuity.
Below are the few types of sync mechanisms discussed.
1. Manual sync is when a user decides to manually sync his offline data to the servers. Using this model, the user will trigger the sync process. It is helpful when the user's network availability is not known. Sync data has to be manually intervened when a conflict occurs.
2. Scheduled sync will initiate the sync process at a scheduled time. While using a scheduler, few factors like device status, network availability, business traffic at a given time have to be considered to ensure a successful sync completion.
3. Push notification sync will be triggered by sending a notification from the server to the client devices. The process can be initiated with or without the user’s intervention on their devices. This method is advisable when there is a business need to keep the client devices up to date.
Reference Architecture
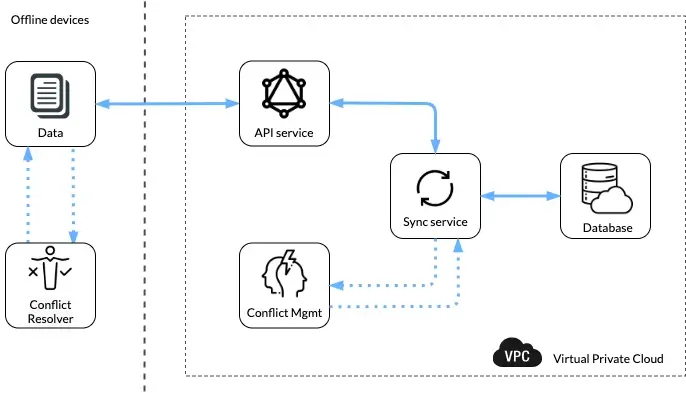
Conflict Handler
Nowadays it is quite common for users to have multiple devices which make handling offline applications more intricate and interesting. A simple conflict can arise when a user syncs his data from two different devices to the server. This can be eliminated if the application has control over choosing which data to be stored. The decision to retain the right data opens up a new paradigm of design choices and architectures.
A change in data is addressed in two stages: Conflict identifier and Conflict resolver.
Conflict identifiers are to check if there are any disputes in the incoming data with the existing ones on the cloud. Once identified, it will move on to the conflict resolving stage.
Conflict resolver can be achieved via various methods like client wins, server wins, time-based resolver, and version control systems.
In the client wins method, the data in the client will override the existing data in the cloud.
For the server wins method, the data in the server will override the conflicting data in the client.
Timebase resolver is when the latest data will be retained in the application irrespective of the data present at the client or server end. To achieve this, the system has to keep track of all timestamps for all the change events while offline.
Version-controlled resolver is similar to the strategy used in git; if a conflict occurs using VCS, the best practice is to let the user choose the particular version of data to be kept in the system.
Conclusion
To conclude, evaluating different variables, mechanisms, and deployment strategies are involved while designing an offline first system. In the above article, few basic parameters are discussed. Stay connected for more comprehensive articles on architectural solutions.
Talk to us for more insights
What more? Your business success story is right next here. We're just a ping away. Let's get connected.
