
Introduction
Welcome to our exploration of recommendation systems! Recent advancements have highlighted the potential of applying graph convolutions to the user-item interaction graph for improved user and item representations. However, much of this progress has focused on contexts lacking contextual information. In this article, we delve into the methodology of recommendation using context-aware data. Join us as we uncover the intricacies of this fascinating field!
Your dataset consists of historical customer interactions across a range of products, serving as the foundation for our predictive analysis. Our objective is to generate forecasts based on input data points. To accomplish this, we will adhere to the following steps:
Load the Dataset: We begin by importing the dataset in CSV format.
Model Training: Next, we train a model using the input data.
Prediction Function: Finally, we create a prediction function that can make predictions for a given input.
Problem Statement
Traditional prediction models often overlook contextual information, resulting in generalized recommendations based solely on past interactions. For instance, if customer C purchases product P, the model may recommend product P to all customers without considering the specific context of the purchase. However, product preferences can vary depending on factors such as location, day of the week, and other contextual variables. To address this limitation, there is a need for prediction models that incorporate contextual information to provide more tailored and relevant recommendations to individual users.
Legacy Solution
The legacy solution is to train the model based on the user and the product order count as a parameter. When a new customer comes in, the product with the maximum count will be shown as the prediction. In the conventional approach, models are trained by considering user-product interactions, often incorporating parameters like product order count. Subsequently, when a new customer interacts with the system, the prediction typically defaults to the product with the highest count.
Drawbacks with Legacy solution
The legacy solution overlooks crucial parameters such as the order date, day, and location, resulting in generic predictions that lack user specificity.
CARS Approach – A Modern Solution
Graph Convolution Machine consists of three components.
Encoder: Captures pertinent features from the input data.
Graph Convolution Layers: Conduct graph convolutions on the user-item interaction graph, enhancing our ability to acquire comprehensive representations.
Decoder: Generates the ultimate recommendations by leveraging the acquired representations.
By incorporating context-awareness, CARS provides more accurate and personalized recommendations, enhancing the overall user experience. As we continue to explore the intersection of graph-based methods and context-awareness, CARS represents a promising direction for the future of recommender systems.
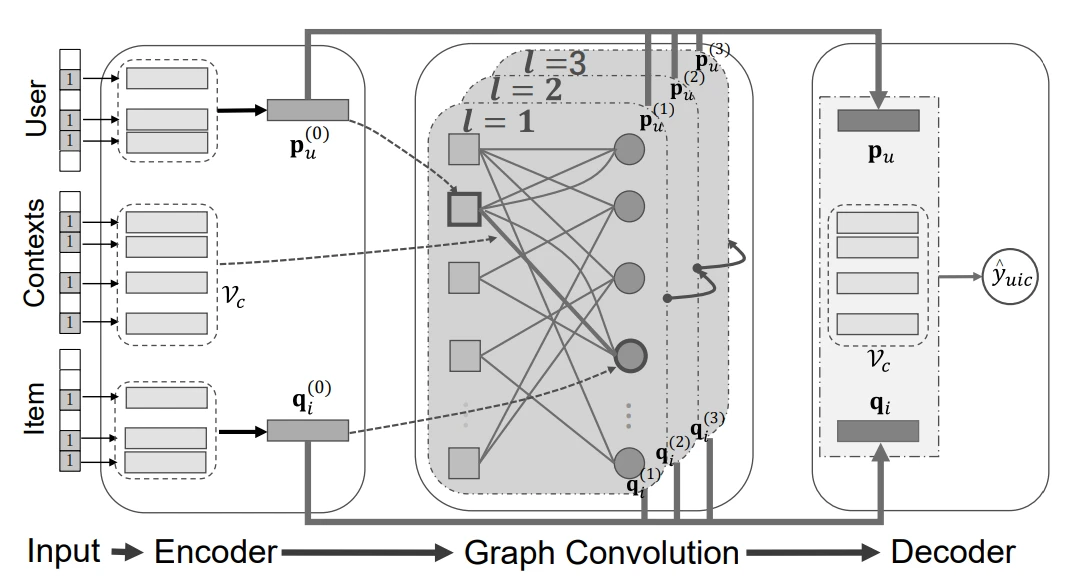
The encoder projects users, items, and contexts into embedding vectors
The vector is passed to the GC layer
The decoder digests the embedding and outputs the prediction
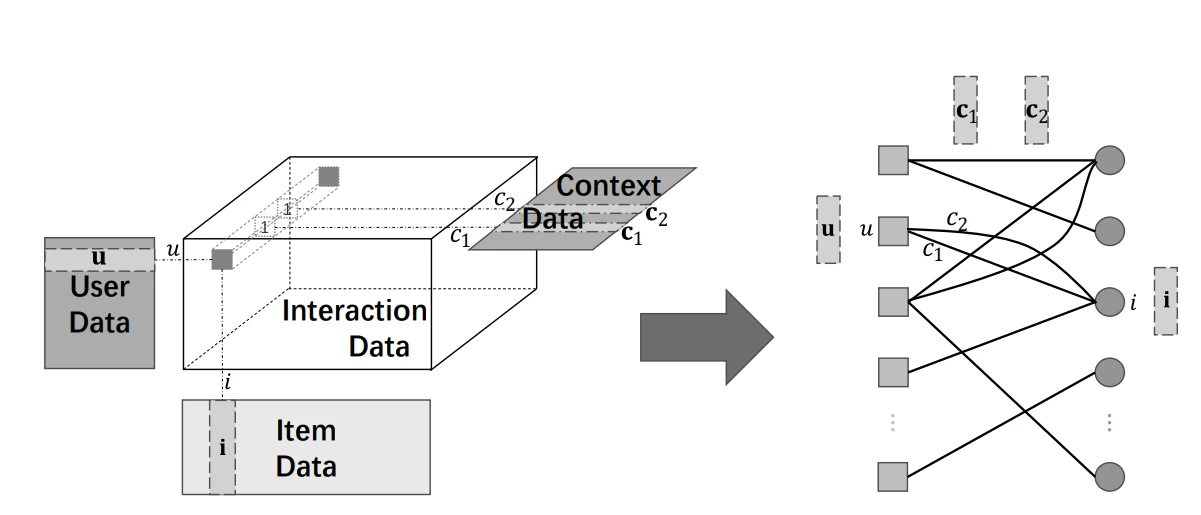
The Data used in CARS can be divided into four types
users, items, contexts, and interactions
columns ['user_id', 'item_id', 'c_year-c_month-c_day-c_DOW-c_last', 'i_price-i_brand']
context column ['c_year', 'c_month', 'c_day', 'c_DOW', 'c_last']
item feature column ['i_price', 'i_brand']
Context
Context is the information associated with an interaction e.g., the current location, time, previous click, etc.
In the Figure below, the main data are the User data and item data, and the sparse tensor is the user-item interaction context vector.
For example, user u includes static user profiles like gender and interested tags, item I includes static item attributes like category and price, and context c includes dynamic contexts like the current location of the user and the time.
There can be multiple edges between user-item pairs since each user can interact with the same items under multiple contexts.
GCM consists of three parts:
Encoder
The encoder consists of the user, item, and interaction context data
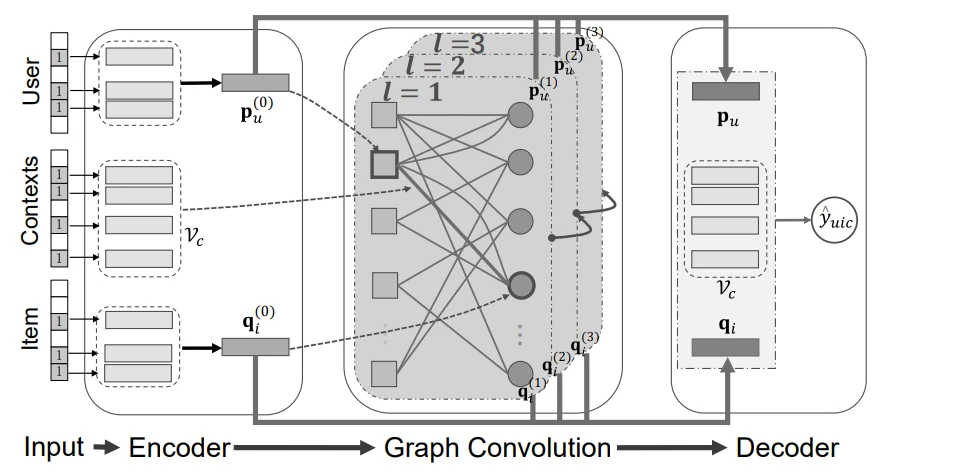
Graph Convolution Layers
The Graph Convolution (GC) module serves as the core component designed to address the constraints of the supervised learning-based CARs module. GC achieves this by taking into account the context surrounding user-item interactions.
For example, a user may prefer bars on Fridays, and a restaurant is more popular at lunchtime. As such, better user and item representations can be obtained if the context features can be properly integrated into the GC.
for bat_users, bat_context, bat_items_pos, bat_items_neg in data_iter:
feed_dict = {self.user_input: bat_users,
self.context_input: bat_context,
self.item_input: bat_items_pos,
self.item_input_neg: bat_items_neg}
loss, _ = self.sess.run((self.loss, self.optimizer), feed_dict=feed_dict)
total_loss += loss Decoder
After the model is trained, we perform one pass of GC layers to obtain the refined representations of all users and items, which can be done offline before online serving. As such, during online serving, we only need to execute the decoder, which has the same time complexity as classic FM (Factorization Machine).
Training
The next step is to start training the model. The training will involve multiple iterations with loss calculation at each step and minimizing the loss.
Prediction
After training, the model file is ready for live prediction. We pass the user and the context data and the system does a prediction based on the vector and provides the list of items that are closer to the given context for the given user.
for user_id, context_id in zip(user_ids, context_ids):
feed_dict = {self.user_input: [user_id] * self.num_valid_items,
self.context_input: [context_id] * self.num_valid_items,
self.item_input: list(range(self.num_valid_items))}
rating_one_user = self.sess.run(self.output_eval, feed_dict=feed_dict)
ratings[cnt, :] = rating_one_user[:, 0]
cnt += 1 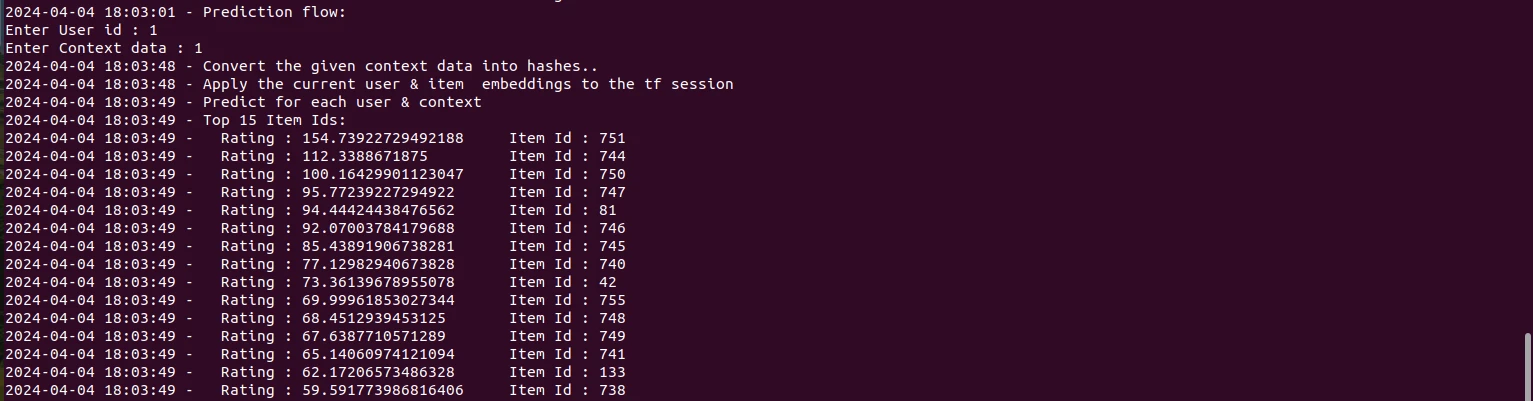
Conclusion
In conclusion, the Context-Aware Recommended System significantly enhances data accuracy by incorporating contextual information, offering a promising avenue for building effective context-aware recommenders. By organizing user behaviors within graphs enriched with contextual details, this approach fosters robust representations for both users and items, ultimately boosting user satisfaction and engagement. Moving forward, further exploration into dynamic contexts like time and evolving user preferences holds immense potential. By integrating additional information beyond user-item interactions, future systems can deliver even more meaningful and accurate recommendations, ensuring continued advancements in recommendation technology.
Possible expansion of the study
The current solution does consider the fixed context. We can also extend this and implement dynamic context e.g. time of action and user-specific dynamic parameters. When these are considered and prediction is done, the accuracy might increase much better than the GCM technique. This scope is something that can be tried and tested in the future.
Industry: Retail - eCommerce
Scenario: An online retail platform wants to recommend products to users based on their past interactions.
Context: Consider factors like the user's location, time and day of purchase, browsing history, and purchase history.
Use Case: Recommending winter coats to users in colder regions during winter months, while recommending swimwear to users in tropical climates.
Hospitality & Travel and Tourism:
Scenario: A travel app aims to provide personalized recommendations for tourist attractions, restaurants, and activities.
Context: Incorporate location, weather, travel companions, and user preferences, day and time of travel.
Use Case: Suggesting family-friendly attractions during weekends or adventure activities for solo travelers. This can also form a travel itenary based on the user preferences.
Music Streaming Services:
Scenario: A music platform wants to recommend songs or playlists to users.
Context: Consider the user's age, gender, location, time of day, and recent listening history and the preferences.
Use Case: Offering calming instrumental music during late evenings or upbeat tracks for morning workouts.
Health and Fitness Apps:
Scenario: A fitness app aims to recommend workout routines or meal plans.
Context: Include user's fitness goals, location (eg, gym or home), and available equipment, user’s health history of ailments.
Use Case: Suggesting high-intensity workouts for users at the gym versus low-impact exercises for home workouts or suggesting based on the user’s health ailment.
News and Content Aggregators:
Scenario: A news app wants to personalize news articles for users.
Context: Consider the user's interests, reading habits, and current events and the reaction of user towards an event.
Use Case: Providing sports news to sports enthusiasts, while offering financial news to users interested in the stock market.
Medical Industry:
Scenario: A Health app wants to diagnose a user based on his lifestyle and provide proactive data for wellbeing.
Context: consider eating/lifestyle habits of the patient, location & its surrounding environmental conditions.
Use Case: Diagnose diseases/disorder that might arise with this set of data and suggest use with a lilfystyle adjustment/health habits that may help them to proactively take action.
Food Industry: Kitchen End
Scenario: A app that will provide the kitchen manager on the list of items that would be requried for prior purchase based on the past history.
Context: Location of the kitchen & the date time of the year and the near by events and the special dishes of the restaurants all lead to a set of data when analyzed will provide us a better understanding of the consumption pattern.
Use Case: When these data’s are analyzed, the kitchen manager will know the approvimate items that needs to be purchased prior to meet demand.
Food Industry: User end
Scenario: A app that might suggest user with the list of restaurants surrounding them.
Context: Location, review & ratings, special events may all lead to restaurants being chosen as most popular one.
Use Case: Providing the most popular restaurants based on the day user selects. Some restaurants may be popular on one day and may not be on the other day.
Talk to us for more insights
What more? Your business success story is right next here. We're just a ping away. Let's get connected.
