
Introduction
In the field of data science and analytics, making sure that your data is accurate, complete, and consistent is extremely important. Data validation is the process of double-checking your data to ensure it meets these criteria. You can use a helpful tool called Great Expectations to ensure your data is reliable when doing data analysis. Great Expectations integrates seamlessly into data pipelines, becoming an indispensable part of the journey from raw data to meaningful insights. This tool brings a proactive approach to data validation, early detection of discrepancies, and consistency checks throughout the pipeline's transformations. In this blog, we will explore what Great Expectations is, why it is essential, its key features, and how to use it to enhance data quality and reliability in your projects.
Great Expectations
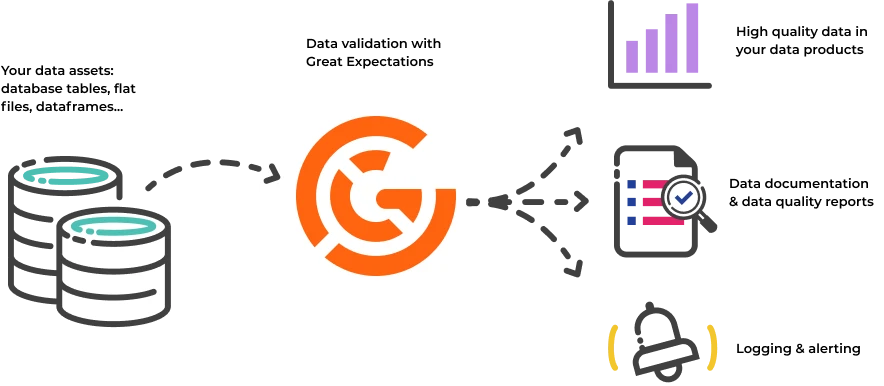
Great Expectations is an open source Python library that helps us to establish data validation, documentation, and test our data pipelines. It allows you to define and maintain expectations about your data, automatically checking whether it meets those expectations. It seamlessly integrates with various tools, including Apache Airflow, Apache Spark, Prefect, dbt, Luigi, and Jupyter Notebooks, providing versatile data validation capabilities across diverse data pipelines and workflow orchestration environments. Let's explore some of its key features.
Key features of Great Expectations
Data Profiling
Great Expectations does not only validate your data it extends its capabilities to offer robust data profiling features. With its profiling functionalities, it allows you to understand your data better by giving detailed insights into things like how columns are distributed, what unique values exist, and various statistical measures. This helps you make smarter decisions when processing and analyzing data. It also acts like a detective, spotting any unusual patterns in the data early on, ensuring that the data you work with is reliable. Moreover, Great Expectations makes this insight-sharing easy by integrating it into its overall documentation strategy, giving everyone involved a complete picture of the data.
During the exploratory phase of a project, data profiling helps analysts and data scientists understand the nature of the data they are working with. It supports identifying patterns, distributions, and potential issues early on.
By understanding the characteristics of different columns, users can set specific expectations that align with the observed patterns, ensuring that the data adheres to certain criteria.
It is used for continuous monitoring, tracking changes in data characteristics over time. This ensures that expectations remain valid as the data evolves.
Data profiling enhances the overall understanding of the dataset. It provides statistical summaries, distributions, and unique value counts, offering a nuanced perspective that goes beyond a superficial examination.
Continuous Integration
Continuous Integration in Great Expectations involves the automated and seamless integration of data validation processes into the development workflow. It ensures that expectations on the data are consistently validated as changes are made to the data pipeline or the dataset itself. Continuous Integration in Great Expectations allows for the early detection of data quality issues, providing a continuous feedback loop for data practitioners.
Continuous Integration is utilized during the development of data pipelines. As new features or transformations are added to the pipeline, CI ensures that the existing data expectations are still met.
When datasets are updated or modified, CI helps in automatically running data validation to ensure that the changes do not introduce data quality issues.
In collaborative data projects where multiple team members are working on different aspects of the data, CI ensures that changes made by one team member do not inadvertently impact the overall data quality.
This is especially crucial in large and complex data projects where manual validation can be a time-consuming process.
Data Documentation
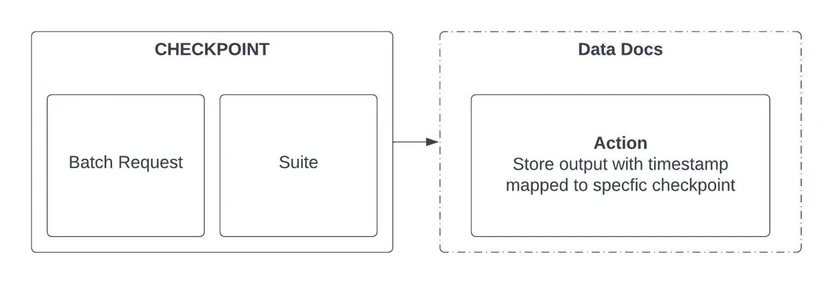
Data documentation in Great Expectations involves the creation and maintenance of comprehensive, human-readable descriptions of your data assets. It goes beyond traditional metadata by capturing the semantics, expectations, and business context of the data. This documentation acts as a living resource, providing insights into the structure, expectations, and quality constraints associated with your datasets. The following diagram provides an example of how the documentation functions within Great Expectations.
gx_dataframe.expect_column_values_to_be_between(column="age", min_value=18, max_value=50)
{
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
},
"meta": {},
"result": {
"element_count": 9,
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_count": 1,
"unexpected_percent": 11.11111111111111,
"unexpected_percent_total": 11.11111111111111,
"unexpected_percent_nonmissing": 11.11111111111111,
"partial_unexpected_list": [
52
]
},
"success": false
}The provided example output indicates the result of a failed expectation in Great Expectations. Here's a brief explanation:
success: Indicates that the expectation has failed (false).
element_count: Total number of elements in the dataset (9 in this case).
missing_count and missing_percent: No missing values in the dataset.
unexpected_count and unexpected_percent: One unexpected value (11.11% of the dataset).
unexpected_percent_total and unexpected_percent_nonmissing: Both reflect the unexpected percentage in different contexts.
partial_unexpected_list: Provides specific values that caused the failure (e.g., the value 52).
Data documentation promotes consistency by providing a standardized format for describing data assets. This consistency is crucial for maintaining a shared understanding of the data across diverse roles within a team.
Data documentation is continuously updated to reflect changes in data expectations, providing an up-to-date reference for users as the data evolves.
Data documentation acts as a bridge between different team members. It ensures that everyone is on the same page regarding the data's structure and expectations, facilitating collaboration.
Custom Expectations
Custom expectations allow data engineers and analysts to define their own rules for what their data should look like. These rules can be as simple or as complex as needed. Custom expectations can be used to validate any aspect of a dataset, from the overall structure to the individual values of each column.
Custom expectations allow data engineers and analysts to validate their data against their specific requirements. This means that they can be used to validate any type of data, no matter how complex.
Custom expectations can be very precise, which means that they can identify data quality issues that may be missed by built-in expectations.
Custom expectations can be reused across multiple datasets. This can save time and effort, and it can also help to ensure consistency across different data sources.
Checkpoint
A checkpoint serves as a pivotal milestone in the data validation journey, encapsulating a set of expectations and validations at a specific point in time within a data pipeline. It acts as a structured mechanism for systematically validating and monitoring data against predefined criteria, ensuring its quality and integrity. Checkpoints provide a historical record of expectations, allowing data engineers to compare and track changes over time. Integrated seamlessly into data workflows, checkpoints enable continuous monitoring, proactive alerting, and adaptive data governance, empowering data practitioners to maintain a reliable and auditable record of data quality throughout its lifecycle.
Components of Great Expectations
Expectations
Expectations serve as declarative assertions about your data. They define what you expect your data to look like. For example, you can expect a column to have a certain data type, a specific range of values following a regular expression pattern, etc.
Suite
A suite is a collection of expectations for a specific dataset or a set of data assets. You can organize suites by data source, data type, or any other logical grouping. Expectations are neatly organized within these suites, making it easy to manage and validate data in different contexts.
Data source
A data source is a configuration that tells Great Expectations where and how to access your data. Whether your data resides in a local file, a remote database, a cloud storage system, or any other source, data sources are essential for defining data connectors.
Data Connector
Data connectors are specific implementations for accessing data from various sources. Great Expectations provides built-in data connectors for a wide range of data storage systems, including CSV, Excel, PostgreSQL, Redshift, S3, and more. If needed, you can even create custom data connectors.
Batch
A batch is a subset of your data, which can be either new data you want to validate or an existing dataset. Great Expectations loads these batches and runs expectations against them. Batch Requests are the primary method for retrieving data in Great Expectations.
Validators
Validators are responsible for running expectations against your data batches. Great Expectations supports various types of validators, including Pandas, Spark, and SQL-based validators, depending on your data processing environment.
Data Docs
Data Docs is a feature that generates documentation for your data validation processes. It creates a user-friendly HTML report summarizing the validation results, displaying data profiling, and showcasing other information about your data. This is a valuable tool for data exploration and fostering collaboration within your team.
Basic Workflow
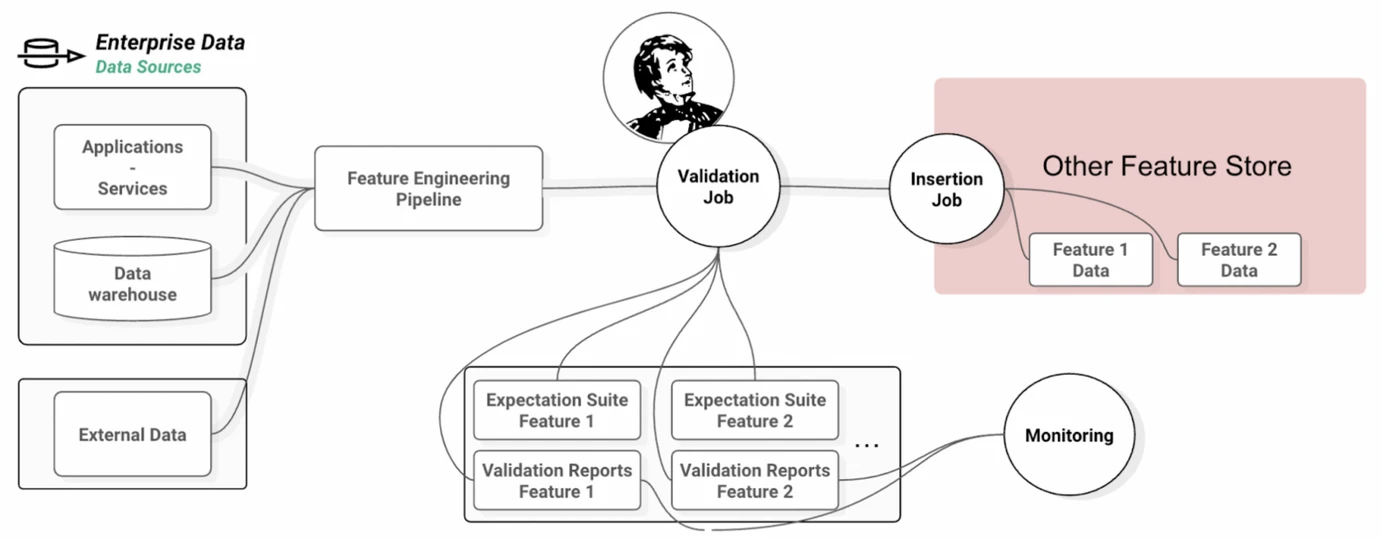
Data Sources Validation:
Great Expectations can validate data from various sources such as data warehouses, applications, and external data.
Validation Mechanism:
Great Expectations enables validation against predefined expectations, which can be specified either through code or a user interface.
Monitoring Capability:
Great Expectations facilitates ongoing monitoring of data quality, allowing for the timely detection and resolution of any arising data quality issues.
Understanding Great Expectations: A Visual Guide
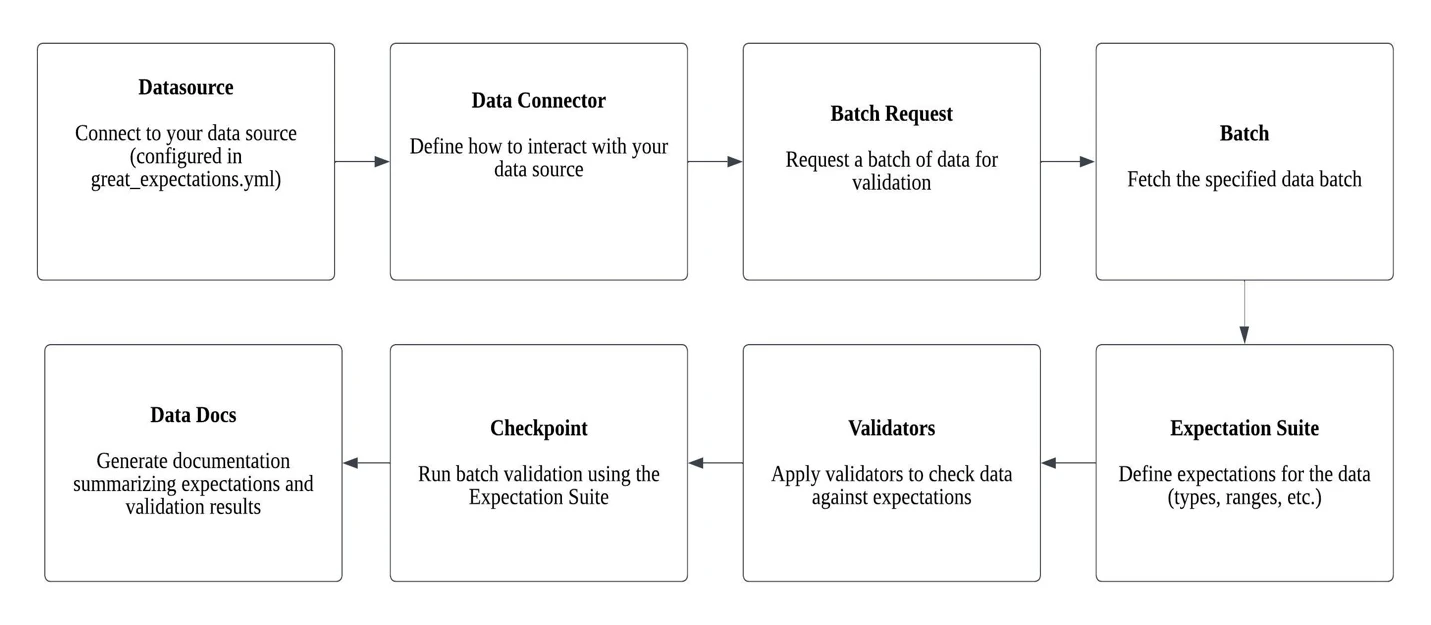
The code below aligns with the visual representation of the steps or processes outlined in the workflow diagram, showing that it works as it should in the described workflow.
import os
import great_expectations as gx
from great_expectations.core.batch import BatchRequest
def run_great_expectations():
current_directory = os.getcwd()
file_path = "great_expectations/"
full_file_path = os.path.join(current_directory, file_path)
# Create a context
# Give the path of the great expectation project
context = gx.data_context.DataContext(full_file_path)
# Create a batch request
# Add the datasource
# Before adding the datasource configure your database
batch_request = {
'datasource_name': 'Employee_datasource',
'data_connector_name': 'default_configured_data_connector_name',
'data_asset_name': 'low_quality_employee_data',
}
# Create a suite name
expectation_suite_name = "low_quality_employee_data.warning"
# Create a validator
validator = context.get_validator(batch_request=BatchRequest(**batch_request),expectation_suite_name=expectation_suite_name)
# List the expectation you want to check in the table
employeeId_check = validator.expect_column_values_to_not_be_null('employeeId')
city_check = validator.expect_column_values_to_not_be_null('city')
if employeeId_check.success and city_check.success:
status = "succeeded"
else:
status = "failed"
print(f"The table {status} to meet all expectations")
print(employeeId_check.result)
print(city_check.result)
# Save the suite
validator.save_expectation_suite(discard_failed_expectations=False)
# Add a checkpoint to mark this point in the data pipeline
context.add_checkpoint(name="data_validation_checkpoint",
batch_request=BatchRequest(**batch_request),
result_format="SUMMARY")
# Build and save the Data Docs to document the data validation process
context.build_data_docs()
context.save_data_docs()
if __name__ == "__main__":
run_great_expectations()
Comparative Analysis of Data Validations in GX and Spark:
| Benefit | GX | Spark |
|---|---|---|
| Data Documentation | GX makes it easy for teams to understand and collaborate on data tasks by providing a powerful way to document and communicate expectations about your data. | Spark's built-in validations might lack easy-to-use documentation features, making it challenging to maintain and share expectations across teams. |
| Declarative Syntax | GX allows users to express expectations using a declarative syntax, making it easier to define complex data validation rules in a way that is intuitive and expressive. | Spark's built-in validations may require more detailed and step-by-step code, potentially resulting in code that is harder to understand and keep up. |
| Dynamic Expectations | GX supports dynamic expectations that can adapt to changing data over time, ensuring ongoing data quality without constant manual intervention. | Spark's built-in validations may lack the flexibility to easily adapt to changing data requirements, potentially requiring frequent updates to validation logic. |
| Centralized Management | GX provides a centralized system for storing, versioning, and organizing expectations, making it easier to track changes and collaborate on data quality efforts. | Spark's built-in validations may lack a centralized management system, potentially leading to scattered validation rules across different components of a Spark application. |
| Extensibility and Customization | GX offers a high degree of extensibility, allowing users to create custom validation functions and integrate with external systems, providing flexibility for unique use cases. | Spark's built-in validations may have limitations in terms of extensibility, potentially restricting users from implementing highly specialized validation logic. |
| Data Profiling | GX includes built-in data profiling capabilities, allowing users to understand the data distribution, unique values, and other statistical measures. | Spark's built-in validations may focus more on basic checks without providing in-depth profiling features, limiting the depth of data exploration. |
Conclusion:
Great Expectations is a powerful tool for ensuring data quality, providing data documentation, and enabling data validation in your Python projects. By incorporating it into your data pipeline, you can maintain confidence in the accuracy and consistency of your data, leading to more reliable analyses and decision-making.
For those seeking a visual walkthrough, kindly refer to theYouTube Video
Talk to us for more insights
What more? Your business success story is right next here. We're just a ping away. Let's get connected.
