
Overview
Organizations today build a multitude of microservices catering to their business needs. Each service stores its data in a database best suited for its purpose. Though the context for a microservice is well-defined, often, the data generated by one is required by a different service or a different solution altogether almost in real-time. This emphasizes the need for a Change Data Capture (CDC) system as part of a company’s software systems. In this blog, building a high availability CDC system focusing on two specific requirements is discussed.
Requirements
1. Complex real-time analysis on data generated from OLTP workloads
Organizations grow by taking informed decisions after analyzing, evaluating, and assessing their business data. With the evolution of Big Data, data analytics, and data warehouse systems - real-time business intelligence has become possible and helps companies in live monitoring, instant decision making, and fraud detection.
2. Reliable asynchronous communication between microservices
Communication between microservices can happen either synchronously (REST/gRPC) or asynchronously (via a message broker). A major concern with asynchronous microservices communication involving a transactional database isdual writes - ie., microservice saving its result into a database as well as sending a message to a downstream service cannot guarantee atomicity between these actions
- ie., microservice saving its result into a database as well as sending a message to a downstream service cannot guarantee atomicity between these actions
Solution Approaches
1. Real-time Complex Analytics on OLTP data
Running complex analytics on OLTP data, assuming they are produced by a bunch of backend applications/services, can be done via multiple ways - here a couple of approaches is discussed
Streaming analytics using a Streaming Platform like Kafka
A CDC application that tracks changes happening in a database and producing them as event streams in Kafka. Stream processing on the events can then be done in one of the following ways.
Kafka Streams
- a client library that can aggregate, perform joins, and windowing on topic data in KafkaksqlDB - an abstraction on top of Kafka Streams used to build stream processing applications using SQL
Spark Streaming - Spark can use Kafka topics as its source for stream processing
Porting the data from OLTP databases to an OLAP datastore/warehouse
Once the data becomes available in Kafka, Kafka Connect - a service to reliably stream data between Apache and other data systems - can be used to stream events into an OLAP datastore, in turn building a data replica of the OLTP database. It provides sink connectors to connect with commonly used public cloud-based OLAP datastores/warehouses
2. Reliable asynchronous Microservices communication
In the case of Dual writes with Microservices, atomicity can be guaranteed by using the same OLTP databases for message passing too. Using CDC to implementOutbox Pattern,reliability can be ensured in message passing to downstream services.
Reference Architecture
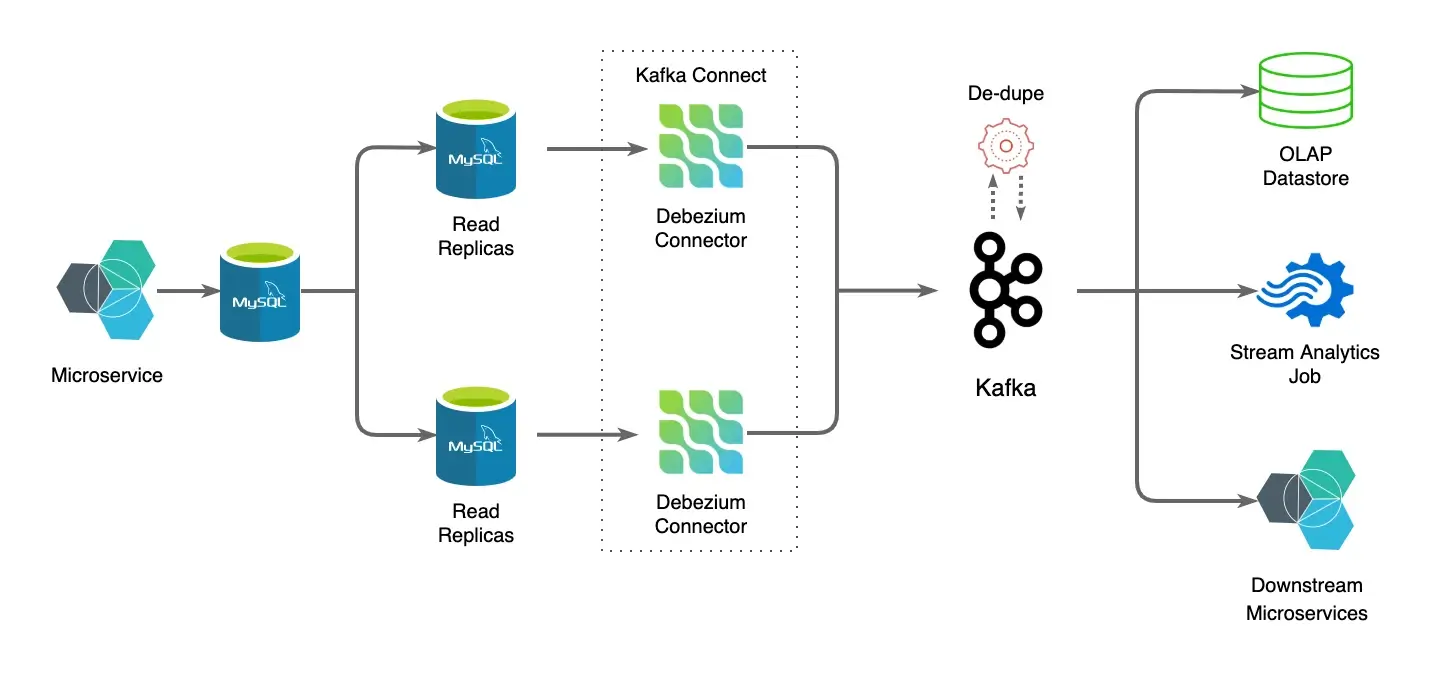
MySQL is taken as the OLTP source database for the reference architecture, andDebeziumis used as the CDC application.
High Availability
With distributed systems, ensuring reliability and availability are paramount. Debezium CDC runs a single thread reading MySQL binlog, making it a potential candidate for a single point of failure in case of network snag and unavailability of upstream systems. Hence replicas are used in order to ensure high availability. Two debezium connectors running on Kafka Connect connected to one MySQL replica each are used.
De-duplicator
A Kafka Streams-based de-duplicator is used to de-duplicate messages between two Kafka topics containing event streams for the same MySQL table from two connectors. De-duplication is done based on the message-ids in the payload, leveraging Kafka streams’ state store.
Talk to us for more insights
What more? Your business success story is right next here. We're just a ping away. Let's get connected.
