
The concept of a data pipeline revolves around automating the transfer of data from one location to another. Typically, data originates from diverse sources and undergoes transformations and optimizations to align with specific business requirements, ultimately enabling the extraction of valuable business insights.
Challenges faced in creating and managing the data pipelines:
The process of integrating various data sources can be quite time-consuming. For instance, when transferring data from Google Cloud Storage (GCS) to Spanner or from Spanner to BigQuery or migrating the data from different sources to a destination, it requires developing a data pipeline code that efficiently combines the various sources and loads them into the destination table.
Developing a data pipeline is a laborious undertaking that entails complexity and demands ongoing maintenance. Even if we already have an existing data pipeline in place and desire to transport data from one point (Point A) to another (Point B) while incorporating certain transformations, we will need to revise the data pipeline and invest additional time into it. Subsequently, thorough end-to-end testing must be conducted before the pipeline can be operationalized.
Furthermore, when integrating services, it becomes necessary to address skill gaps and allocate time toward identifying best practices for seamless service integration. Additionally, adopting methods that optimize performance becomes imperative.
This blog explores the role of Data Fusion in facilitating the creation of data pipelines with a sample use case scenario.
Data Fusion: A Code-Free Approach to Building Data Pipelines
Data Fusion is a fully managed, Cloud Native tool that helps in efficiently building, managing, and integrating data pipelines. It helps in focusing on extracting meaningful information from data rather than building and managing the data pipeline codes. Built on top of CDAP (Cask Data Application Platform), an open-source tool, Data Fusion provides a user-friendly drag-and-drop interface for creating and managing Extract, Transform, Load (ETL), and Extract, Load, Transform (ELT) pipelines. This visual approach empowers users to design pipelines by simply arranging pre-built components and connectors.
How Data Fusion solves the problem?
Data Fusion is a powerful Google Cloud web-based tool that enables the creation and management of data pipelines. It eliminates the need for infrastructure management, allows for code-free data transformations, and addresses common data-related challenges like Data Ingestion, Data Integration, and Data Migration. Its capabilities encompass both batch and real-time processing, supporting organizations in deriving valuable insights and facilitating informed decision-making.
Use Cases for Data Fusion: From Batch Processing to Real-Time Streaming:
Data Fusion is a versatile tool that addresses various use cases related to data integration, processing, and managing data. Some of the common use cases that Data Fusion handles include:
Data Warehouse: Data Fusion Pipeline makes it easy to move data from one source to another without the need for coding.
Data Migration: Data Fusion simplifies the process of migrating data from legacy systems to the cloud for better performance and functionality. It also enables seamless data movement between different Google Cloud Platforms, enhancing data interoperability and maximizing the benefits of cloud infrastructure.
Data Consolidation: Data Fusion assists in retrieving data from multiple sources and consolidating it into a single source, providing a comprehensive view of the data from various sources. Before loading the data into a single source, transformations can be applied to the data obtained from different sources. This allows for better insights and analysis of the combined data.
Master Data Management: It is a process that helps organizations gather and organize important data from different places into one central location. This data, known as master data, includes crucial information like customer details, product information, and employee records. By bringing all this data together in one place, organizations can ensure that everyone is using the same accurate and up-to-date information.
Data Consistency: Data Fusion helps ensure that data from different sources is consistent. For example, if an organization wants to expand or move data to a hybrid cloud environment, Data Fusion allows them to run data pipelines either on-premises or across different clouds. This ensures that the data remains consistent throughout the process. Additionally, Data Fusion helps in removing any duplicate data while loading it into the target source.
Data Fusion Pipeline Creation:
Creating a Data Fusion instance is the initial step in utilizing the Data Fusion service. It allows you to set up a dedicated environment where Data Fusion Pipelines can be built and executed for effective data integration and management.

After successfully creating a Data Fusion instance, you can proceed to create data pipelines using the Data Fusion Studio. The Data Fusion Studio is a user-friendly graphical interface provided by the Data Fusion service that allows you to visually design and configure data pipelines.
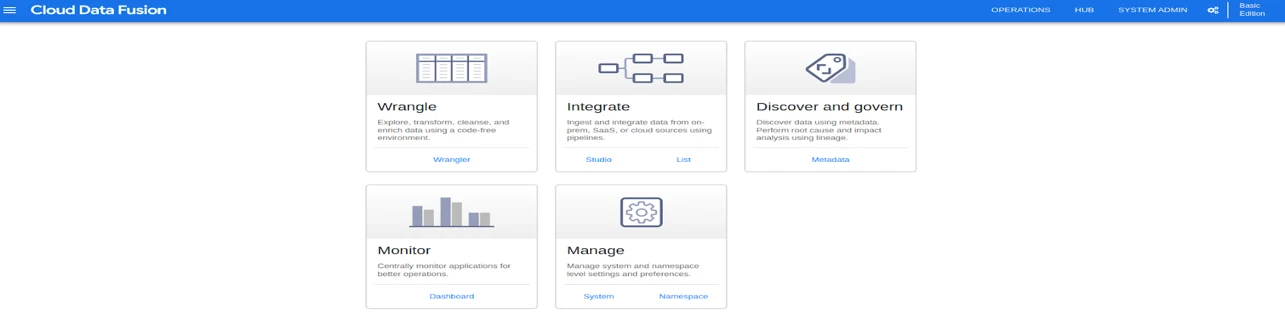
Data fusion studio will have a list of options to create a data pipeline.
Source: The source helps in establishing a connection to the database, file system, and real-time batch streams from which we gather the data. Without writing a single piece of code we can connect to the data source and fetch data.
Transform: Data Obtained from the source might not be in a cleaner format or some data needs to be manipulated in order to store the data in a destination like timestamp format changing, changing the data type of a column, transforming a value, etc. All types of data transformation can be done using the Transform.
Analytics: The Analytics plugin is used for applying operations like group by, join operations on input records, deduplication of input records, and using alias names for the columns.
Conditions and Actions: Using the Conditions plugin, we can choose pipeline flow based on the previous execution evaluated as true or false. It offers flow control through the means of conditions.
The action plugin is for executing custom actions that are intended to execute during the workflow but not for manipulating the data. If we want to track the pipeline job status daily, we can add an action to populate the pipeline status in the db at the end of the pipeline.
Error Handlers and alerts: When pipeline nodes get error values, or null values and want to capture them, one can use an error collector's plugin to catch the errors. It can be connected to any transform plugin or analytics plugin output and process these results in a separate error pipeline flow, or an error collector plugin can be connected to a sink plugin to store the results in a location and examine it later.
Alerts publishers let us publish notifications when uncommon events occur. Downstream processes can then subscribe to these notifications to trigger custom processing for these alerts.
Once the plugins are selected and configurations are added to form the pipeline, we can save and deploy the pipeline.
Once it is deployed, we can see the deployed pipelines in the pipelines list.
Transforming Data with Data Wrangler: A Flexible Tool for Structuring and Cleaning Data
Wrangler in Data Fusion is a user-friendly tool that helps you clean and transform your data without needing to write any code. It's a visual interface where you can connect to different data sources, see your data, and easily apply changes to make it better.
Imagine a scenario where an educational organization collects student data from multiple colleges. Each college maintains its student database with different formats and column structures. To consolidate this data for analysis, the organization uses Data Fusion.
With Data Fusion, they can easily connect to each college's database to load the sample data and apply transformations through a simple interface. These transformations standardize the data by adjusting column names, and data types, and handling missing values. Once the transformations are set, they save the configuration and let Data Fusion automatically execute the pipeline. The transformed data is then loaded into a central database, providing a unified view of student information. By using Data Fusion, the organization streamlines the consolidation process without the need for any complex transformation codes. They can quickly merge student data from different colleges, ensuring consistency and facilitating analysis.
In summary, Data Fusion simplifies the consolidation of student data from multiple colleges. It enables easy connections, transformation applications, and data loading. This simplifies the management and analysis of student information across colleges.
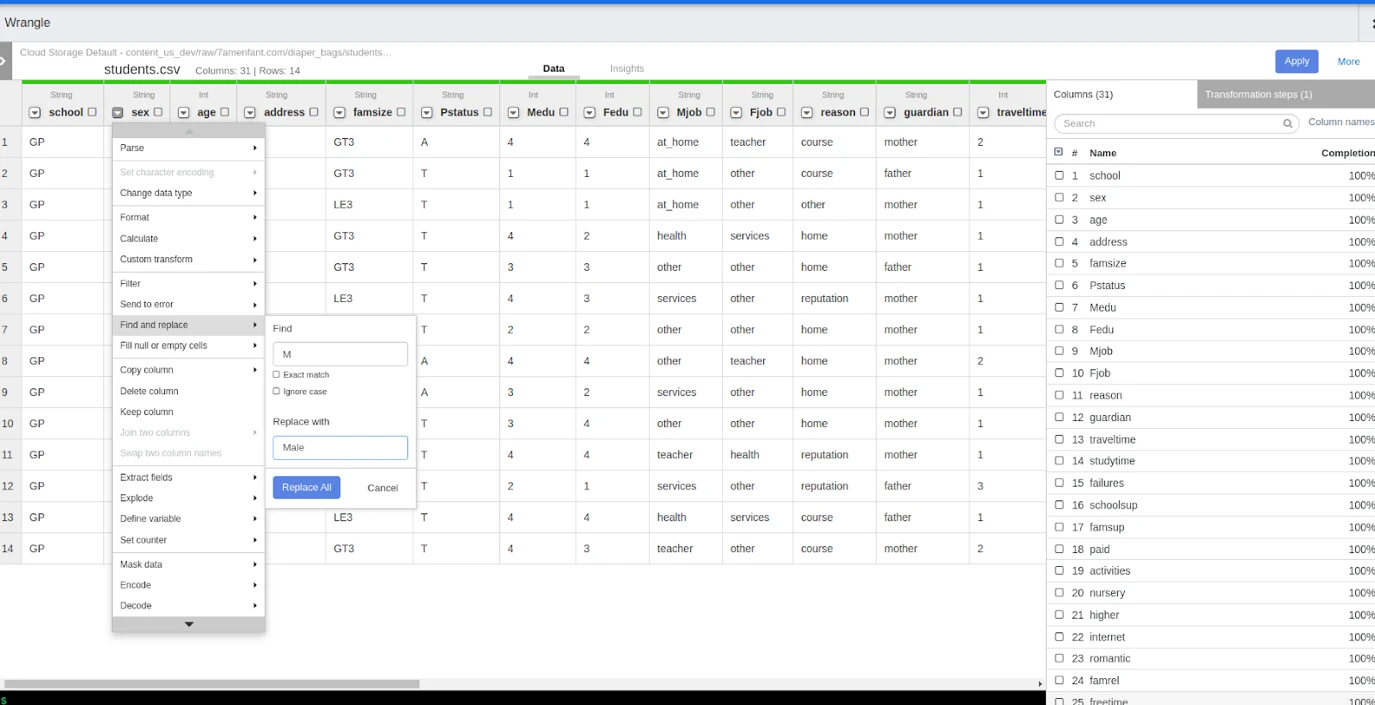
Once saved it will take to the wrangler properties page and in the actions, tab click on “propagate” to propagate the changes to the next pipeline node.
Real-Life Scenario: Streamlining Sales Data Integration for Retail Companies:
In a real-life scenario, imagine a retail company that collects sales data from various stores and wants to consolidate and analyze this data in Big Query for better insights. By implementing a daily data transfer job, the company can effortlessly move the sales data from Google Cloud Storage (GCS) to Big Query.
This process requires writing code to read the data from GCS, and sometimes data transformations may be needed before loading it into Big Query. To execute this data transfer as a daily job, it is necessary to incorporate it into the Google Composer Environment and run it as a Directed Acyclic Graph (DAG).
To achieve this, one needs to spend time understanding the Google Composer Environment and writing the necessary code as a DAG. This involves configuring and deploying the job within the Composer environment. It is important to familiarize oneself with the Composer environment and understand how to create and schedule DAGs to ensure a successful and automated daily data transfer from GCS to Big Query.
Overall, the process entails understanding the environment, writing the code, and deploying it as a DAG within the Google Composer Environment to accomplish the daily data transfer task.
Approach 1: Traditional Data Pipeline using Composer Environment:
Airflow Job Script for loading GCS to BigQuery
Below sample script is provided for illustrative purposes only. Certain details such as error handling and robustness have been omitted for brevity.
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import pandas as pd
from google.cloud import storage
import os
cwd = os.getcwd()
def gcs_to_bg():
gcp_file = "tempdb_backup/sales_data.csv"
download_google_storage_files(gcp_file)
df = pd.read_json(f"{cwd}/gcs_file.txt")
for index, row in df.iterrows():
active_value = row["active"]
if active_value == "t":
active_value = True
else:
active_value = False
df.at[index, "active"] = active_value
df.to_gbp("stores_dataset.sales_data", if_exists="append")
def download_google_storage_files(gcp_file):
storage_client = storage.Client("project_1")
bucket = storage_client.get_bucket("usa")
blob = bucker.blob(gcp_file)
blob.download_to_filename(f"{cwd}/gcs_file.txt")
with DAG(
dag_id = "sales_data_dag", start_date = datetime(2021, 1, 1), schedule_interval="0 2 * * *", catchup=False
) as dag:
task1 = PythonOperator(task_id="sales_data", python_callable=gcs_to_bg)
task1In the provided script, an Airflow DAG has been written to automate a data processing task. The DAG is scheduled to run daily at 2 AM. The task involves downloading a file from GCS, applying transformations to the file, and uploading it to Big Query.
However, if the file size becomes larger, it may be necessary to modify the approach. Instead of directly loading the entire file into a data frame, alternative methods can be explored. One option is to load the data in smaller chunks or batches, allowing for more efficient processing. Another approach is to utilize the Spark framework, which is designed for handling large-scale data processing. By leveraging Spark, the data can be loaded into a data frame and subsequently loaded into Big Query.
These alternative approaches help address the challenge of handling larger file sizes by introducing strategies that optimize data processing and mitigate potential performance issues.
Approach 2: Same Data Pipeline using Data Fusion:
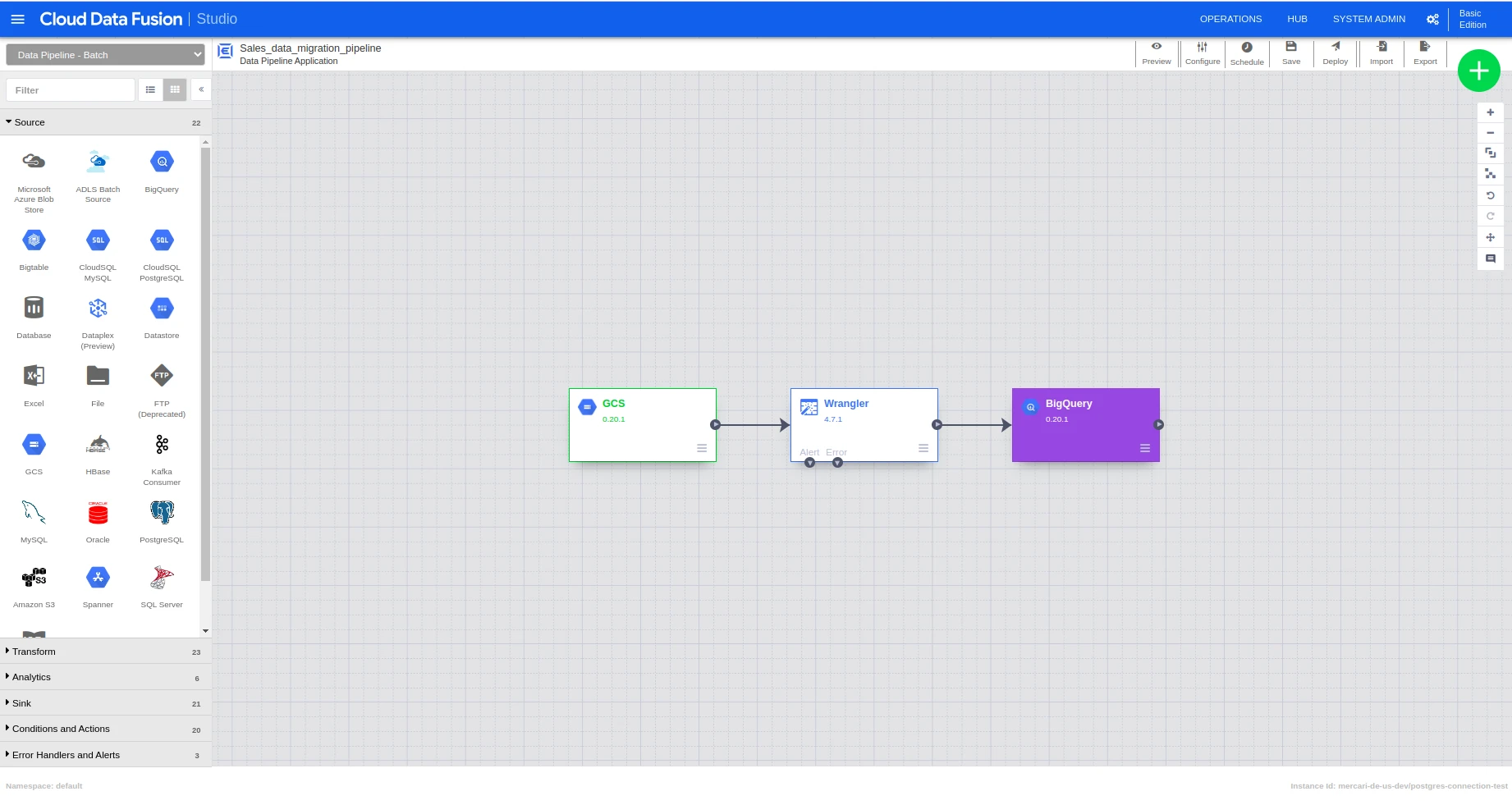
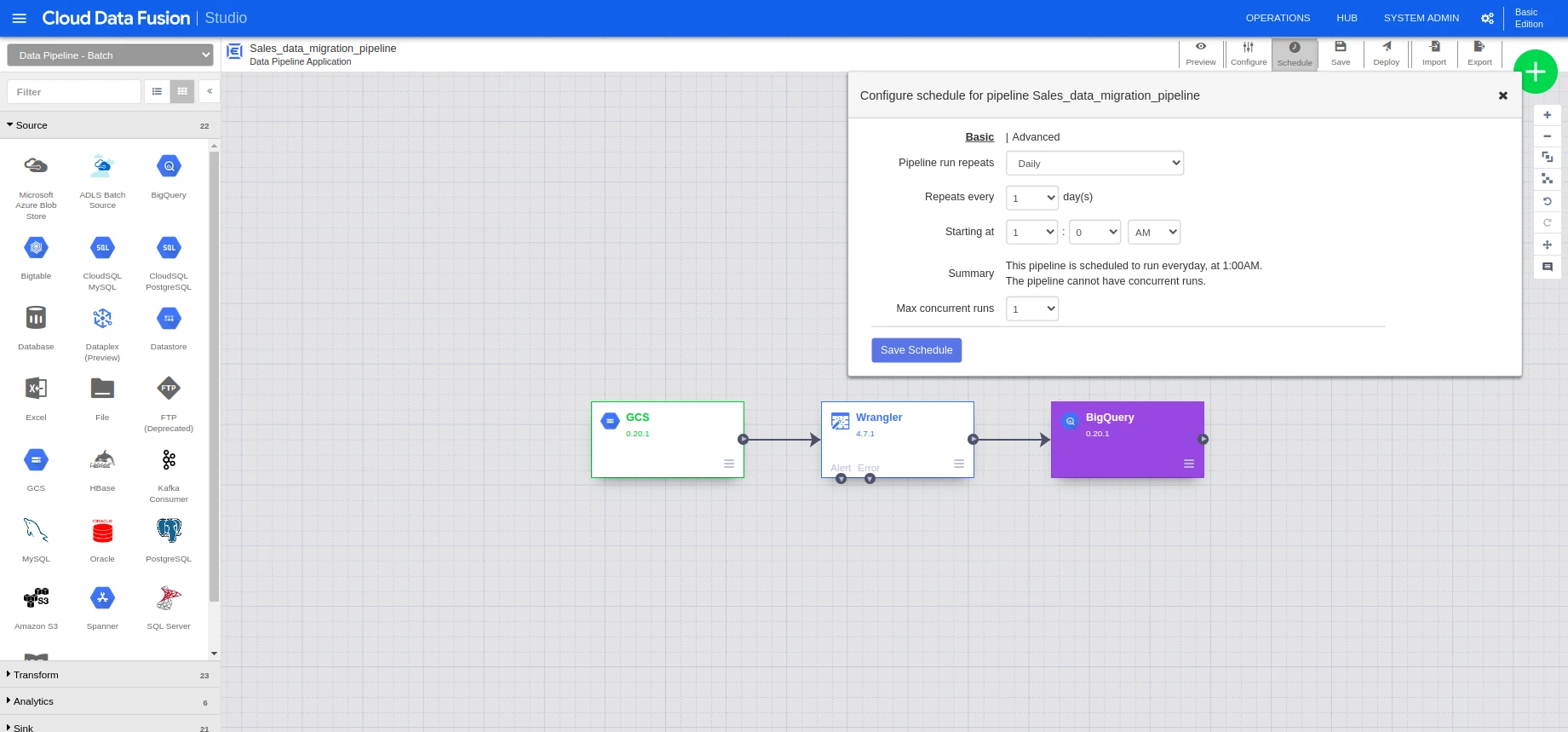
Using Data Fusion, we can just pick the source, sink, and apply data transformation using the wrangler and deploy it. Once the deployment is done, we can go to the pipeline page and click on the schedule tab and schedule the job accordingly.
To load the data from GCP to Big query, we need to pick source, sink, and wrangler to apply the transformation.
The second step will be configuring the GCS source by entering the GCS path and service account JSON if required. Once the configuration is done, we need to propagate the changes to the next part. Configuration can be propagated by selecting the propagate option in the action drop-down.
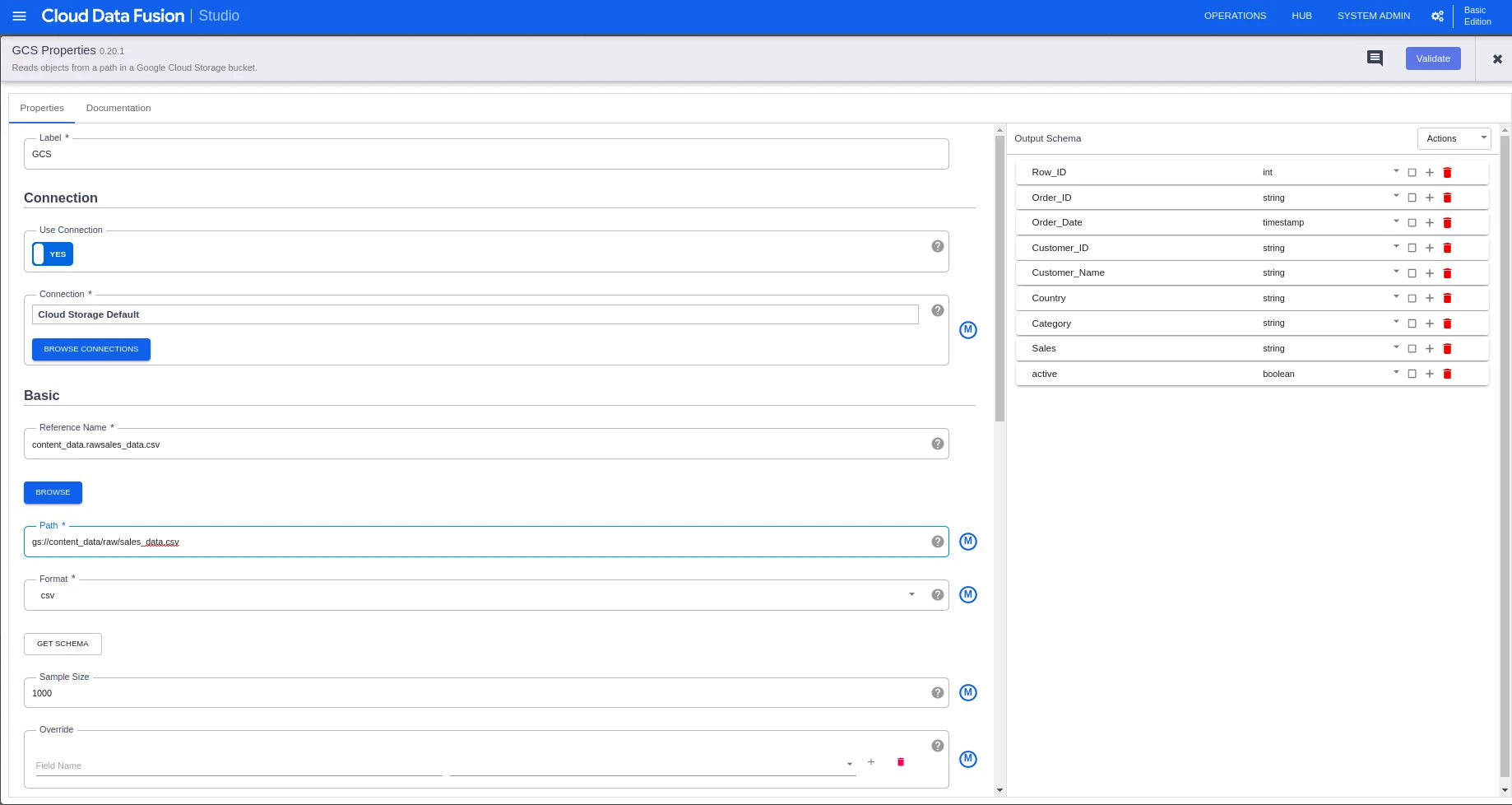
We can apply data transformation in the wrangler part and propagate the changes to sink (BigQuery).
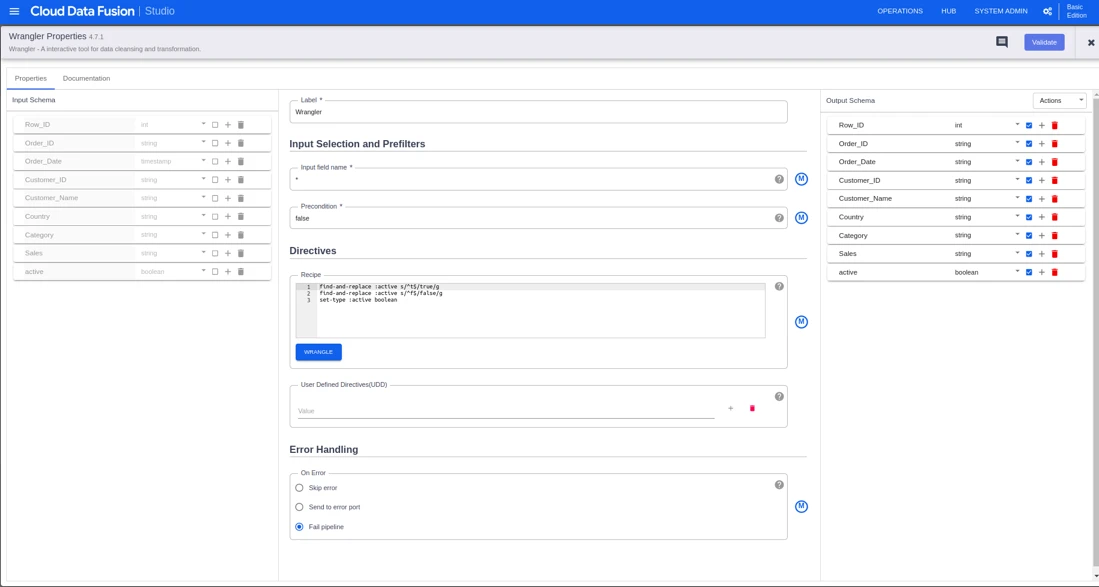
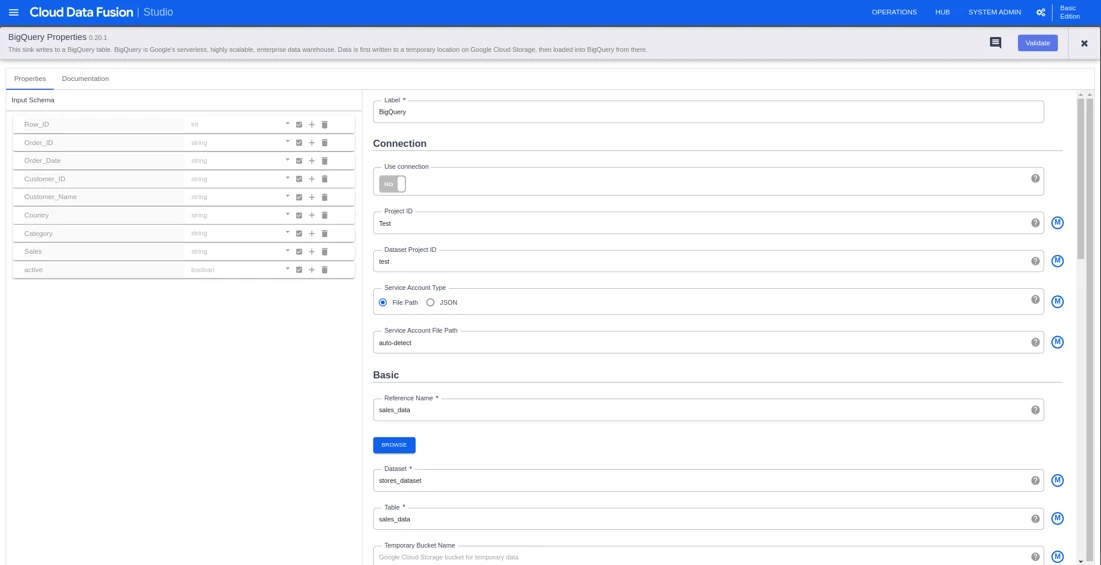
In the BigQuery sink, configure the table name, and dataset to load the transformed data to BigQuery and deploy it.
Once the deployment is done, we can go to the pipelines page and schedule the pipeline. The job will run at the scheduled time, and we don’t need to worry about the file size and do any changes in the implementation of Data Fusion if the file size continues to grow or in the data fusion studio page itself, we can be able to schedule the data fusion pipeline.
Scenarios where we need to consider choosing Data Fusion as an option:
Data Fusion can integrate data from a wide variety of sources but the data coming from different sources can be in different types. The heterogeneous nature of data requires complex transformation to load the data to a destination.
Data Fusion can be used for integrating real-time data pipelines, despite that it is well suited to building batch pipelines. To build a real-time data pipeline, you might want to consider services like Data Stream.
Conclusion: Empowering Enterprises with Next-Gen Data Pipeline Solutions
In the previous sections, we discussed the concept of Data Fusion, its use cases, and how it addresses common data integration challenges. We also explored a sample implementation of a Data Fusion pipeline.
Data Fusion essentially simplifies the process of fetching data from multiple sources and loading it into a specific destination. It eliminates the need to worry about infrastructure development, adhere to coding best practices, and perform ongoing maintenance work. This reduces the learning curve for individuals who want to introduce transformations or changes to the data.
When traditional data loading approaches involve writing scripts, it requires a deep understanding of the underlying infrastructure before making any modifications. This allows individuals to quickly grasp the concepts of pipelines and make necessary changes more efficiently compared to modifying code. It is possible to integrate the data from other sources like MongoDB, Cassandra, etc. by developing our custom plugins by building them with Maven and converting it into a JAR plugin
In summary, Data Fusion offers a code-free approach to data integration, making it easier and faster to learn and implement data pipelines. It empowers users to introduce required changes without the complexities of infrastructure development, coding, and extensive maintenance
Talk to us for more insights
What more? Your business success story is right next here. We're just a ping away. Let's get connected.
